Monday, June 30, 2008
A Decision Theoretic Framework for Ranking using Implicit Feedback
Friday, June 27, 2008
Bill Gates Retirement Party: The Best Bill Gates Parodies Ever
The Best Bill Gates Parodies Ever
 So what does Bill Gates really have to show for his years of hard work? Sure he built a software empire, and yeah he has been known as the richest man alive. But those things aren't as cool as being immortalized on film and in song. Maybe. Either way, he's been cartooned, acted, clayed, and even sung about. So with Bill's retirement only days away, we thought it was only fitting we gave you a mash-up of all these green sweater, glasses wearin' characters.
So what does Bill Gates really have to show for his years of hard work? Sure he built a software empire, and yeah he has been known as the richest man alive. But those things aren't as cool as being immortalized on film and in song. Maybe. Either way, he's been cartooned, acted, clayed, and even sung about. So with Bill's retirement only days away, we thought it was only fitting we gave you a mash-up of all these green sweater, glasses wearin' characters. If you didn't already guess which videos were used above, here's a list. There's The Simpsons, Celebrity Death Match, South Park, 2DTV, Freakazoid and of course Pirates of Silicon Valley.
What about the song you say? Well, it's by a group called, wait for it, Komputer. The song is titled, wait for it, "Bill Gates", and is the third track on their 1997 album The World of Tomorrow. If you can't seem to get the song out of your head, you can buy it on both iTunes and Amazon.com.
At the end of this week Bill Gates will leave his post at Microsoft, but his various TV and film characters will live on forever. Since Ballmer will be taking over, we can only hope that he gets the same treatment, cause a crazy-ass cartoon character of that guy would be hilarious.
Thursday, June 26, 2008
Watch autoload magic live
We all know that in development mode Rails auto loads most of the changes. However it would be nice if in the log you can see message like ‘Class Person is being loaded’. ‘Class Person is being unloaded’.
Well you can have that. Put this line of code at the bottom of your environment.rb file and you will be able to watch the magic.
# log all auto loading stuff in the log file
Dependencies.log_activity = true
The above code will produce following type of output.
Dependencies: called new_constants_in("Helpers", :Object)
Dependencies: New constants: PreferencesHelper
Dependencies: loading /Users/nkumar/scratch/xxxx/app/helpers/preferences_helper.rb defined PreferencesHelper
Dependencies: called require_or_load("/Users/nkumar/scratch/xxxxx/app/helpers/project_memberships_helper.rb", nil)
Dependencies: loading /Users/nkumar/scratch/xxxxx/app/helpers/project_memberships_helper
Dependencies: called load_file("/Users/nkumar/scratch/xxxxx/app/helpers/project_memberships_helper.rb",
["Helpers::ProjectMembershipsHelper", "ProjectMembershipsHelper"])
Dependencies: removing constant MilestonesHelper
Dependencies: removing constant OrganizationalMembershipsHelper
Dependencies: removing constant OrganizationsHelper
Dependencies: removing constant PeopleHelper
Dependencies: removing constant PreferencesHelper
Nice. Seeing is believing.
Wednesday, June 25, 2008

Monday, June 23, 2008
Something new about null values
public class Weird {
public static void main(String[] args) {
throw null;
}
}
Apparently it compiles, and expectedly throws an NPE at runtime. So, why does it compiles if throw statement accepts only subtypes of Throwable and null is not instance of Throwable? The JLS specification states that "The null reference can always be cast to any reference type", but then in above example compiler does not require main method to throw throwable. Weird, eh?
Update: The answer is of course in the Java Language Specification:
"A throw statement first evaluates the Expression. If the evaluation of the Expression completes abruptly for some reason, then the throw completes abruptly for that reason. If evaluation of the Expression completes normally, producing a non-null value V, then the throw statement completes abruptly, the reason being a throw with value V. If evaluation of the Expression completes normally, producing a null value, then an instance V' of class NullPointerException is created and thrown instead of null. The throw statement then completes abruptly, the reason being a throw with value V'."
evhead: Will it fly? How to Evaluate a New Product Idea
Will it fly? How to Evaluate a New Product Idea
 I've been thinking about a number of new product ideas lately. In doing so, I've been trying to come up with a way more structured way of evaluating them. Here's a first attempt at defining that. It's not as clear as I'd like it to be. But perhaps you'll find it useful.
I've been thinking about a number of new product ideas lately. In doing so, I've been trying to come up with a way more structured way of evaluating them. Here's a first attempt at defining that. It's not as clear as I'd like it to be. But perhaps you'll find it useful.
Tractability
Question: How difficult will it be to launch a worthwhile version 1.0?
Blogger was highly tractable. Twitter was tractable, but sightly less-so because of the SMS component. Google web search had quite low tractability when they launched it. Vista?: About as low as you can get.
Tractability is partially about technical difficulty and much about timing and competition—i.e., How advanced are the other solutions? Building a new blogging tool today is less-tractable, because the bar is higher. Building the very first web search engine was probably pretty easy. Conversely, building the very first airplane was difficult, even though there wasn't any competition.
In general, if you're tiny and have few resources, tractability is key, because it means you can build momentum quickly—and momentum is everything for a startup. However, tractability often goes hand and hand with being early in a market, which has its own drawbacks (e.g., obviousness, as we'll discuss below).
If you're big and/or have a lot of resources—or not very good at spotting new opportunities, but great at executing—a less-tractable idea may be for you. It may take longer to launch something worthwhile, but once you crack the nut, you have something clearly valuable.
Obviousness
Question: Is it clear why people should use it?
Everything is obvious once its successful. Big wins come when you can spot something before its obvious to everyone else. There are several vectors to this: 1) Is it obvious why people should use it? 2) Is it obvious how to use? 3) Is it an obviously good business?
Number two is more affected by the design of the product than the idea itself. You don't actually want number three to be true. You want it to be a good business, but not an obviously good business, because than you get more competition. Web search was not an obviously good business before Google demonstrated it. This allowed them to leap-frog the competition that was in it for years, but not taking it very seriously. But, like Google, the business may not be clear until later.
The key question for evaluating an idea is number one: Is it obvious why people should use it? In most cases, obviousness in this regard is inversely proportional to tractability. The cost of Blogger and Twitter's high tractability was the fact that they were defining a new type of behavior. The number one response to Twitter, still, is Why would anyone do that? Once people try it, they tend to like it. But communicating its benefits is difficult. We're heartened by the fact that Why would anyone do that? was the default response by the mainstream to blogging for years, as well, and eventually tens of millions of people came around.
On the flip side, if you can build an ad network that makes people more money, a better search engine, or a productivity app that actually does tasks for people—all, less-tractable solutions—it will be highly obvious to people why to use your product.
Sometimes you can come up with ideas that are highly tractable and obvious. For example: Top Friends or HotOrNot. These products were not hard to launch and yet, were immediately appealing (to their target market). What was not obvious, in either case, is that they could also be great businesses. HotOrNot has proven this to be true. And I suspect Slide will, as well.
Deepness
Question: How much value can you ultimately deliver?
The most successful products give benefits quickly (both in the life of a product and a user's relationship with it), but also lend themselves to continual development of and discovery of additional layers of benefit later on.
Facebook is incredibly deep because it leverages your connections, which touch practically every aspect of your life. Scrabulous, on the other hand—a Facebook app for playing Scrabble—is not very deep. How big is the Scrabble-playing part of your life, and how much can it deliver beyond that?
But most things are deeper than they seem at first glance. Practically any application, once people start using it, can be used as a lever to more activity and benefit delivery. Being smart about what you're leveraging is key.
When Feedburner first launched, their only feature was the ability to take an RSS feed and spit out multiple versions, depending on the capabilities of the feed reader requesting it. It seemed useful, but hardly something to start a company around, especially because that particular problem would probably go away over time. Or so I thought. What I didn't get and they did (because Dick and gang is smarter than me) is that they were setting themselves up at a great leverage point—between publishers and their readers—where they could offer an ever-deeper value stack. Soon it was feed stylesheets with one-button subscription, feed stats, feed flare, blog stats, email subscriptions, and, of course, advertising, where they made their money.
While we're talking about Feedburner, its worth mentioning that their product was also very obvious for their core user-base. There were clear benefits and very little drawbacks. They also had no competition, even though there were tons of companies in the RSS/feed space, because most of the others were battling it out on the reader side.
Other times, you stumble into deepness. When they put up HotOrNot on a whim, Jim and James didn't know they'd be able to leverage it into a highly profitable dating site. Okay, so HotOrNot's still not the "deepest" of sites, but it's deeper than you think.
Wideness
Question: How many people may ultimately use it?
Wideness, like deepness, is a fairly classic market analysis measure. They are usually inversely proportional—do you try to offer the mass-market good or the niche one?
Feedburner is not particularly wide. Their market was those who published RSS feeds (and cared about them). This was in the hundreds of thousands, not a hundred million. Turns out, it didn't need to be used by a hundred million to be worth a hundred million, so going for wideness is not entirely necessary. But it's something to look at.
Like deepness, wideness can take you by surprise. The web is getting so damn big, what seem like niche ideas can be very decent businesses. When Ted Rheingold launched Dogster, as a joke, he didn't know there were enough people out there who would be interested in making their dogs web pages to actually build a business. When we launched Blogger, I thought maybe a few thousand people would use it.
Sometimes, you can find a spot that is both deep and wide. This is where multi-billion-dollar businesses are built: Google, Windows, Ebay. It's easy to think these kinds of opportunities aren't laying around anymore—at least not for the little guy. But most people would have said the same before Facebook entered the picture.
Discoverability
Question: How will people learn about your product?
I was going to call this criteria "viralness." However, there's a lot of focus on viralness these days, and—while sometimes amazingly effective—it's not the only way to grow a user-base. And it doesn't make sense in all cases.
Interesting to note: Google web search is not the least bit viral. Nor is Firefox. Nor it Kayak.
It's possible to get the word out without being "viral." One way is organic search traffic. Another is pay-per-click ads (if you can monetize). Another is plain old-fashioned word-of-mouth/blog/press. (Twitter has probably grown more through press and blogs references than any inherent viralness.) There's also distribution deals and partnerships.
Either way, it's something to think about up front, as different ideas lend themselves to different discoverability strategies. And some things are more difficult than others to spread. Dating sites, for instance, have not historically been viral, because people weren't going to invite their friends to—or even talk much about—their personal ads. The sites made up for this by buying lots of ads, which worked because they monetized signups via subscription.
Monetizability
Question: How hard will it be to extract the money?
Far be it for me to say that obvious monetizability is a requirement. I'm generally a believer that if you create value, you can figure out the business. However, all things being equal, an idea with clear buck-making potential is better than one without.
Whether or not something is monetizable is not always clear up-front. It wasn't clear how Google was going to make money early on. Ebay thought it would sell auction software.
In most cases, if you position yourself close to the spending of money, you can extract some. Or if you offer something that clearly saves or makes people money.
Blogger, I believe, makes money for Google, but it's not the most monetizable of products. Twitter, I believe, will be more-so, but that's yet to be seen.
Personally Compelling
Question: Do you really want it to exist in the world?
Last on the list, but probably the first question I ask myself is: How important to me is it that this product exists in the world? If I were evaluating a startup, I'd ask this of the founders. As I wrote in "Ten Rules":
Great products almost always come from someone scratching their own itch. Create something you want to exist in the world. Be a user of your own product. Hire people who are users of your product. Make it better based on your own desires.
In theory, you can get around this with lots of user research. (It's pretty clear neither Slide nor Rockyou's founders are creating widgets based on their own needs and desires.) But you're more likely to get it wrong that way. When I've gone sideways, it's when I wasn't listening to my gut on this issue. Specifically, Blogger and Twitter were personally compelling, while Odeo wasn't.
However, "personally compelling" doesn't have to mean only that you want it as a user yourself. Curing cancer or helping the world be more green may be highly personally compelling for other reasons, which I think is just as good. My favorite products are those I really want as a user, but that I also think have some "greater good."
Charting it Out
To bring it home, here's a table with my estimates on where different products land by these criteria. Obviously, these are subjective measures, and for some of them, it's hard to judge in retrospect. (I didn't inlclude Personally Compelling on the list, because I can't really speak to the founder's motivations in most cases.)
| Product | Tractability | Obviousness | Deepness | Wideness | Discoverability | Monetizability |
|---|---|---|---|---|---|---|
| Blogger | Very High | Low | High | High | High | Low |
| Google (web search) | Very Low | Very High | Very High | Very High | Low | Very High |
| High1 | High | Very High | High | Very High | High2 | |
| High | Low | High | High | High | Med | |
| Feedburner | Med | High | High | Med | Med | Med3 |
| HotOrNot | Very High | Very High | Med | Med | Med | High4 |
| Scrabulous | High | Very High | Low | Low | Very High | Low |
| Ebay | Med | High | Very High | Very High | High | Very High |
1 I don't actually know what Facebook consisted of in version 1.0. It was actually in what looked like an untractable space (MySpace competitor), but applying the constraint of college-only made the competition non-existent and the usefulness and tractability potentially very high from the start.
2 In theory
3 Unsure
4 Only in the case of "Meet Me at HotOrNot," the dating side of the site. The original, rating side probably has low monetizability.
Friday, June 20, 2008

Wednesday, June 18, 2008
Build Your Own Reddit With Reddit
 Social news site Reddit's secret announcement -- which people have been speculating about for the past 24 hours -- is out of the bag: Reddit is open sourcing their code. "We've always strived to be as open and transparent with our users as possible, and [open sourcing our code] is the next logical step," said Reddit in a blog post. Reddit, which was built and maintained by just 5 people, also posted a list of the more than 15 other open source projects that the site relies on.
Social news site Reddit's secret announcement -- which people have been speculating about for the past 24 hours -- is out of the bag: Reddit is open sourcing their code. "We've always strived to be as open and transparent with our users as possible, and [open sourcing our code] is the next logical step," said Reddit in a blog post. Reddit, which was built and maintained by just 5 people, also posted a list of the more than 15 other open source projects that the site relies on.
The code is available at an official Trac page and is licensed under the Common Public Attribution License, which means that anyone running the code must publish changes publicly, but that the software is free for commercial use. Some of Reddit's code is not being made public, mostly stuff that deals with anti-spam and anti-cheating algorithms, according to Reddit.
"Since reddit's beginning, we have stood on the shoulders of giants in the open source world. Every library, tool and platform we depend on is open," said the announcement blog post. "Until now, the only portion of reddit that wasn't freely available is reddit itself. We are proud and excited that we're finally giving back to the community that has given us so much."
It makes sense for Reddit, which has grown because of very passionate and technically savvy community, might go this route. Open sourcing Reddit's code will very likely lead to a stronger product and tighter community, and not to the birth of strong competitors. Anyone who wants to create niche Reddits on topics that the site doesn't adequately cover is now free to do so, however.
Reddit is written in Python. An explanatory video from the company is below.
Tuesday, June 17, 2008
Spam, Phishing, and Online Scams: A View from the Network-Level
 Spam, Phishing, and Online Scams: A View from the Network-Level
Spam, Phishing, and Online Scams: A View from the Network-Levelgoogletechtalks
1 hr 6 min - Jun 17, 2008
Google Tech Talks
June, 13 2008
ABSTRACT
The Internet is overrun with spam: Recent estimates suggest that spam
constitutes about 95% of all email traffic. Beyond simply being a
nuisance, spam exhausts network resources and can also serve as a
vector for other types of attacks, including phishing attacks and
online scams. Conventional approaches to stopping these types of
attacks typically rely on a combination of the reputation of a
sender's IP address and the contents of the message. Unfortunately,
these features are brittle. Spammers can easily change the IP
addresses from which they send spam and the content that they use as
the "cover medium" for the email message itself. In this talk, I will
describe a new, complementary approach to stopping unwanted email
traffic on the Internet: Rather than classifying spam based on either
the content of the message or the identity of the sender, we classify
email messages based on how the spam is being sent and the properties
of the spamming infrastructure. I will first summarize the highlights
of a 13-month study of the network-level behavior of spammers using
data from a large spam trap. I will then describe a new approach to
spammer classification called "behavioral blacklisting" and present a
detailed study of network-level features that can be used to identify
spammers. Often these features can classify a spammer on the first
packet received from that sender, without even receiving the message.
I will conclude by describing our plans to incorporate these
algorithms into a next-generation sender reputation system, as well as
our ongoing study of the online scam hosting infrastructure, whose
properties may also ultimately prove useful for identifying unwanted
traffic.
This talk includes joint work with Anirudh Ramachandran, Nadeem Syed,
Maria Konte, Santosh Vempala, Jaeyeon Jung, and Alex Gray.
Speaker: Nick Feamster
Nick Feamster is an assistant professor in the College of Computing at Georgia Tech. He received his Ph.D. in Computer science from MIT in 2005, and his S.B. and M.Eng. degrees in Electrical Engineering and Computer Science from MIT in 2000 and 2001, respectively. His research focuses on many aspects of computer networking and networked systems, including the design, measurement, and analysis of network routing protocols, network operations and security, and anonymous communication systems. His honors include a Sloan Research Fellowship, the NSF CAREER award, the IBM Faculty Fellowship, and award papers at SIGCOMM 2006 (network-level behavior of spammers), the NSDI 2005 conference (fault detection in router configuration), Usenix Security 2002 (circumventing web censorship using Infranet), and Usenix Security 2001 (web cookie analysis).
Monday, June 16, 2008
Amazon Prime Filter Exists!
One of my biggest complaints in the past about Amazon's Prime shipping membership was that it was too difficult to filter Amazon's inventory for products that were eligible for free shipping. What good is a free shipping program if you can't figure out which products quality and which are shipping from 3rd parties?
This doesn't only effect Prime members. Anyone who'd rather buy from Amazon directly benefits, including people like myself who are sick of receiving print catalogs from Amazon's 3rd party suppliers after buying something through Amazon. Stop that.
Now, what do we have here from the left margin of Amazon:
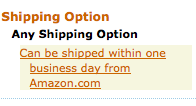
A link that filters search results for Amazon.com's own inventory: the product eligible for Amazon Prime. Nice!
A delicately worded link that does exactly what I was looking for.
Problem solved.
Thursday, June 12, 2008
Thrift: (slightly more than) one year later
A lot has happened in the year since we released Thrift. First and foremost, Thrift has gained a lot of cool features:
- Support for C#, Perl, Objective C, Erlang, Smalltalk, OCaml, and Haskell.
- More idiomatic style in Java and Ruby.
- Two new protocols: one for dense encoding and one using JSON syntax.
- Significant speed boost in Python using a C module and PHP using an extension.
I'm even more excited about some of the stuff being worked on now.
- Here at Facebook, we're working on a fully asynchronous client and server for C++. This server uses event-driven I/O like the current TNonblockingServer, but its interface to the application code is all based on asynchronous callbacks. This will allow us to write servers that can service thousands of simultaneous requests (each of which requires making calls to other Thrift or Memcache servers) with only a few threads.
- Powerset's Chad Walters and I are working on templatizing the C++ API. This will be an almost entirely backward-compatible change that will preserve all the flexibility of the Thrift API, but it will allow performance-conscious developers to add type-annotations that will improve serialization and deserialization speed by about 5x and 3x respectively.
- Thrift's Ruby mapping, which never got much attention here at Facebook, has had a surge of popularity amongst our external contributors. It's getting some much-needed attention from Powerset's Kevin Clark and our newest corporate contributor: RapLeaf. They've already got an accelerator extension in testing (which works like the existing Python and PHP accelerators) and are working on some serious style overhauls. At least, that's what they tell me. I don't know Ruby, so I mostly leave them alone. :)
- Ross McFarland has been working on a C mapping for Thrift using glib. A C mapping has been one of our oft-requested features, so it's great to see this finally taking shape.
- There are a host of other features that are "on the back burner" for now, but which I expect to be incorporated eventually. These include patches that we received for an asynchronous Perl client, an SSL transport for C++ (based on GNU TLS), and a more robust file-based transport.
If you are interested in Thrift, the best documentation is still the original whitepaper. You can also check out Thrift's new homepage. Most of the interesting updates are on the Thrift mailing lists (subscription info on the homepage). Thrift's Subversion repository has just moved into the Apache Incubator repository. Information on accessing it is available on the Thrift homepage. A lot of experimental development is published in the unofficial Git repository.
Wednesday, June 11, 2008

10 Worst Woman-Bashing Ads
It all started with domestic ads in the 1950s. “Honey, I want to get your shirts whiter! But how do I do it?” It was a serious quandary women appeared to face at the time.
These days, there’s no question those old ads are sexist. But woman-bashing is far from over. It has only taken on a different, more sexual guise. According to these ads, women are built for male satisfaction. If problems arise–too much talking, disobedience, ugliness–simply deflate them, drink a lot of beer, or appease them with diamond jewelry.
These ads say it all. Here are ten of the industry’s finest:
10. This ad depicts a plain-looking woman getting more attractive with each sip of a beer. When the beer runs out, she’s–gasp–plain again.
9. “Made by hand?” Wishful thinking.

8. They mean kicking from the inside, right? Not her abusive boyfriend kicking her belly from the outside?

7. According to this ad, it’s easy to buy her good behavior:

6. Do not get married. Your wife will become a hideous grandmother with pinned-up hair. Your mistress, however, will always remain hot and available.

5. England’s Sun newspaper ran this billboard ad on the sides of buses. She looks like she’s for sale—and not for very much.

4. Notice the double meaning of the word. American Apparel’s entire ad campaign is based on borderline ads like these.

3. This Australian commercial has been dubbed the “Smartest Man in the World” commercial. Moral of the story: women always trap you into large, messy family situations, and they never use birth control.
2. This Czech ad starts with a couple on the beach. The woman is complaining about something. The man, thirsty and tired of her yapping, deflates her and goes to have a beer with his buddies.
1. This notorious German Heineken commercial created the ultimate Fembot. She’s a hot, roboticized, self-cloning Christina Aguilera lookalike who serves beer out of a keg in her uterus. They call her “Minnie Draughter,” and she’s the ideal beer wench-cum-hot dancing chick.
Tuesday, June 10, 2008
Cookies are for Closers » LinkedIn Architecture
LinkedIn Architecture
At JavaOne 2008, LinkedIn employees presented two sessions about the LinkedIn architecture. The slides are available online:
- LinkedIn - A Professional Social Network Built with Java™ Technologies and Agile Practices
- LinkedIn Communication Architecture
These slides are hosted at SlideShare. If you register then you can download them as PDF’s.
This post summarizes the key parts of the LinkedIn architecture. It’s based on the presentations above, and on additional comments made during the presentation at JavaOne.
Site Statistics
- 22 million members
- 4+ million unique visitors/month
- 40 million page views/day
- 2 million searches/day
- 250K invitations sent/day
- 1 million answers posted
- 2 million email messages/day
Software
- Solaris (running on Sun x86 platform and Sparc)
- Tomcat and Jetty as application servers
- Oracle and MySQL as DBs
- No ORM (such as Hibernate); they use straight JDBC
- ActiveMQ for JMS. (It’s partitioned by type of messages. Backed by MySQL.)
- Lucene as a foundation for search
- Spring as glue
Server Architecture
2003-2005
- One monolithic web application
- One database: the Core Database
- The network graph is cached in memory in The Cloud
- Members Search implemented using Lucene. It runs on the same server as The Cloud, because member searches must be filtered according to the searching user’s network, so it’s convenient to have Lucene on the same machine as The Cloud.
- WebApp updates the Core Database directly. The Core Database updates The Cloud.
2006
- Added Replica DB’s, to reduce the load on the Core Database. They contain read-only data. A RepDB server manages updates of the Replica DB’s.
- Moved Search out of The Cloud and into its own server.
- Changed the way updates are handled, by adding the Databus. This is a central component that distributes updates to any component that needs them. This is the new updates flow:
- Changes originate in the WebApp
- The WebApp updates the Core Database
- The Core Database sends updates to the Databus
- The Databus sends the updates to: the Replica DB’s, The Cloud, and Search
2008
- The WebApp doesn’t do everything itself anymore: they split parts of its business logic into Services.
The WebApp still presents the GUI to the user, but now it calls Services to manipulate the Profile, Groups, etc. - Each Service has its own domain-specific database (i.e., vertical partitioning).
- This architecture allows other applications (besides the main WebApp) to access LinkedIn. They’ve added applications for Recruiters, Ads, etc.
The Cloud
- The Cloud is a server that caches the entire LinkedIn network graph in memory.
- Network size: 22M nodes, 120M edges.
- Requires 12 GB RAM.
- There are 40 instances in production
- Rebuilding an instance of The Cloud from disk takes 8 hours.
- The Cloud is updated in real-time using the Databus.
- Persisted to disk on shutdown.
- The cache is implemented in C++, accessed via JNI. They chose C++ instead of Java for two reasons:
- To use as little RAM as possible.
- Garbage Collection pauses were killing them. [LinkedIn said they were using advanced GC's, but GC's have improved since 2003; is this still a problem today?]
- Having to keep everything in RAM is a limitation, but as LinkedIn have pointed out, partitioning graphs is hard.
- [Sun offers servers with up to 2 TB of RAM (Sun SPARC Enterprise M9000 Server), so LinkedIn could support up to 1.1 billion users before they run out of memory. (This calculation is based only on the number of nodes, not edges). Price is another matter: Sun say only "contact us for price", which is ominous considering that the prices they do list go up to $30,000.]
The Cloud caches the entire LinkedIn Network, but each user needs to see the network from his own point of view. It’s computationally expensive to calculate that, so they do it just once when a user session begins, and keep it cached. That takes up to 2 MB of RAM per user. This cached network is not updated during the session. (It is updated if the user himself adds/removes a link, but not if any of the user’s contacts make changes. LinkedIn says users won’t notice this.)
As an aside, they use Ehcache to cache members’ profiles. They cache up to 2 million profiles (out of 22 million members). They tried caching using LFU algorithm (Least Frequently Used), but found that Ehcache would sometimes block for 30 seconds while recalculating LFU, so they switched to LRU (Least Recently Used).
Communication Architecture
Communication Service
The Communication Service is responsible for permanent messages, e.g. InBox messages and emails.
- The entire system is asynchronous and uses JMS heavily
- Clients post messages via JMS
- Messages are then routed via a routing service to the appropriate mailbox or directly for email processing
- Message delivery: either Pull (clients request their messages), or Push (e.g., sending emails)
- They use Spring, with proprietary LinkedIn Spring extensions. Use HTTP-RPC.
Scaling Techniques
- Functional partitioning: sent, received, archived, etc. [a.k.a. vertical partitioning]
- Class partitioning: Member mailboxes, guest mailboxes, corporate mailboxes
- Range partitioning: Member ID range; Email lexicographical range. [a.k.a. horizontal partitioning]
- Everything is asynchronous
Network Updates Service
The Network Updates Service is responsible for short-lived notifications, e.g. status updates from your contacts.
Initial Architecture (up to 2007)
- There are many services that can contain updates.
- Clients make separate requests to each service that can have updates: Questions, Profile Updates, etc.
- It took a long time to gather all the data.
In 2008 they created the Network Updates Service. The implementation went through several iterations:
Iteration 1
- Client makes just one request, to the NetworkUpdateService.
- NetworkUpdateService makes multiple requests to gather the data from all the services. These requests are made in parallel.
- The results are aggregated and returned to the client together.
- Pull-based architecture.
- They rolled out this new system to everyone at LinkedIn, which caused problems while the system was stabilizing. In hindsight, should have tried it out on a small subset of users first.
Iteration 2
- Push-based architecture: whenever events occur in the system, add them to the user’s "mailbox". When a client asks for updates, return the data that’s already waiting in the mailbox.
- Pros: reads are much quicker since the data is already available.
- Cons: might waste effort on moving around update data that will never be read. Requires more storage space.
- There is still post-processing of updates before returning them to the user. E.g.: collapse 10 updates from a user to 1.
- The updates are stored in CLOB’s: 1 CLOB per update-type per user (for a total of 15 CLOB’s per user).
- Incoming updates must be added to the CLOB. Use optimistic locking to avoid lock contention.
- They had set the CLOB size to 8 kb, which was too large and led to a lot of wasted space.
- Design note: instead of CLOB’s, LinkedIn could have created additional tables, one for each type of update. They said that they didn’t do this because of what they would have to do when updates expire: Had they created additional tables then they would have had to delete rows, and that’s very expensive.
- They used JMX to monitor and change the configuration in real-time. This was very helpful.
Iteration 3
- Goal: improve speed by reducing the number of CLOB updates, because CLOB updates are expensive.
- Added an overflow buffer: a VARCHAR(4000) column where data is added initially. When this column is full, dump it to the CLOB. This eliminated 90% of CLOB updates.
- Reduced the size of the updates.
[LinkedIn have had success in moving from a Pull architecture to a Push architecture. However, don't discount Pull architectures. Amazon, for example, use a Pull architecture. In A Conversation with Werner Vogels, Amazon's CTO, he said that when you visit the front page of Amazon they typically call more than 100 services in order to construct the page.]
The presentation ends with some tips about scaling. These are oldies but goodies:
- Can’t use just one database. Use many databases, partitioned horizontally and vertically.
- Because of partitioning, forget about referential integrity or cross-domain JOINs.
- Forget about 100% data integrity.
- At large scale, cost is a problem: hardware, databases, licenses, storage, power.
- Once you’re large, spammers and data-scrapers come a-knocking.
- Cache!
- Use asynchronous flows.
- Reporting and analytics are challenging; consider them up-front when designing the system.
- Expect the system to fail.
- Don’t underestimate your growth trajectory.
Thursday, June 5, 2008
Radiohead's "Nude" performed by a ZX Spectrum, dot matrix printer, scanner, and hard disk array

Wednesday, June 4, 2008
06/4/08 PHD comic: 'When to meet with your advisor'
| Piled Higher & Deeper by Jorge Cham | www.phdcomics.com | |
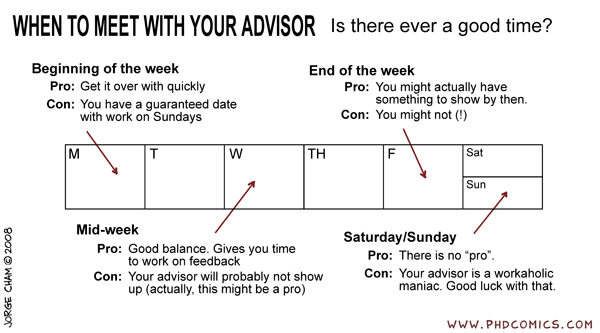 | ||
title: "When to meet with your advisor" - originally published 6/4/2008 For the latest news in PHD Comics, CLICK HERE! | ||

Yahoo is releasing an Address Book API today that will give 3rd-party developers access Yahoo users’ contact lists without the traditional, but primitive, method of page scraping.
In addition to searching for specific contacts and fields and reading their data, developers can use it to add contacts and change existing records (although to start, only pre-approved developers will have the right to make edits).
Chris Yeh, the head of the Yahoo developer network, considers this release the second major “proof point” of Yahoo’s Open Services (YOS) campaign, which kicked off at the Web 2.0 Expo in March. The first point was Search Monkey, which makes it possible for anyone to enhance the way website results are displayed in Yahoo search.
As with Microsoft and Google’s own contact APIs, Yahoo has decided to implement a proprietary permission system - theirs called bbAuth - rather than implement an open protocol like oAuth. Yeh says he hopes to see oAuth adopted by Yahoo in the near term, although he couldn’t say when that might happen.
LinkedIn and Plaxo are two launch partners who have already implemented the new API and even used it publicly over the past several months.
Yeh says there is no policy in place for restricting how long developers can store and use the data they pull from the API. But, as with many of its developer initiatives, Yahoo reserves the right to stop what it deems bad behavior.
As Dave McClure suggested to me recently, it would be very powerful if developers could not only retrieve basic contact information from webmail services like Yahoo, Hotmail and Gmail, but could also determine the types of relationships a user has with those contacts. For example, if I wanted to pull out a user’s top 5 contacts, I could do so by looking at the frequency of messages sent to all contacts. This lookup could be refined by targeting only messages with certain keywords so that contacts belonging to particular categories (say, golf enthusiasts) could be identified by their messages.
Unfortunately, no such advanced querying is available with Yahoo’s new API, at least to start. Yeh does assure me that other groups within the YOS campaign are looking at how to identify relationships within the address book, so hopefully we’ll see this type of functionality down the line.
Crunch Network: CrunchBoard because it’s time for you to find a new Job2.0
Monday, June 2, 2008
Express Your Music Mood with Muzicons Widgets

Social networking woes got you down? Why don’t you let the world know how frustrated you are by expressing your emotions through a music widget!
Muzicons is a new music sharing site where you can easily create a widget (or Muzicon) to host on your blog. The name, like to ‘emoticon,’ comes from the ability to use icons to show mood, emotions, and whatever it is you are thinking at the time.

Unlike some of the music widgets that exist such as eSnips, MxPlay, and Sonific, Muzicons is the only service that gives users the option of choosing an emoticon and a mood status. You can customize the look of your widget and place it in your Blogger, LiveJournal, Wordpress or MySpace.

Muzicons may seem ordinary, but they’re David against the Goliath that is the music industry. Since Muzicons was created in Russia, it will not have to adhere to the demands of the DMCA as we saw happen with Imeem when it was sued by Warner Music. Users are free to upload copyrighted music as they see fit.
In my opinion, Muzicons are simply the cutest music widgets I have ever seen.
Check out my Muzicon:

Facebook certainly chose a peculiar time to announce the imminent death of a platform (and dare I say, operating system) staple: the installation screen.
In the late afternoon of last Friday, Pete Bratach penned a post called “Streamlining Application Authorization” that went virtually unnoticed by the press at the time, even by Facebook-focused blogs. And when they did finally cover Bratach’s post, they chose to focus on less important matters concerning user metrics.
Was Facebook trying to pull a fast one on us? That wouldn’t be surprising, given the potential of fundamental platform changes to upset a large number of developers. And what it did announce consisted of quite a fundamental change.
Starting July 15 (and perhaps coinciding with the rollout of Facebook’s new site design), users will no longer see an installation screen (see below) when they access an application for the first time. Rather, they will see a new “login” screen that simply asks them whether they want to permit the application access to their information. This simply grants the application temporary access to your data so it can operate, without establishing any real footprint on your Facebook experience.

The new screen has been designed to make application adoption less intimidating for users. They will no longer have to worry about installing (and later uninstalling) applications - and their associated profile boxes, left-hand nav buttons, profile links, and email lists - just to try them out.
But the change should also slow viral growth patterns - especially for newer, smaller apps. Gone is the ability to put profile boxes (which give apps considerable visibility) on users’ pages upon first access. To add a box (on a special apps tab no less), users must later decide that they like it well enough to click on a special canvas page button.
The same goes for email notifications and news feed items larger than one line; users must opt into these through the canvas page as an afterthought. The new design will also forgo app links in the left-hand column (the column is going away in its present form), as well as app links under profile pictures. All in all, these changes mean that applications will struggle to obtain the same visibility and user access that they can instantly achieve now upon installation.
The move to get rid of installations is the latest in a line of decisions meant to clamp down on spammy apps by implementing sweeping changes to the platform, rather than coming down hard on particular wrongdoers. We first covered this trend in August when Facebook moved to stop developers from generating deceptive profile boxes and messages, and then changed the way all applications are measured.
Later, Facebook outed misleading notifications and mini-feed stories, reined in cross-application notifications, and put restrictions on feed stories. More importantly, Facebook began regulating the number of notifications, requests, and emails that apps could send to new users, based on response rates. And this year the company also released a formal platform policy that implemented rule-based limitations in addition to technical ones.
Platform changes meant to reduce spam are great for users but not so great for developers, even the non-spammy ones. After all, platforms by definition are meant to be stable; shake them up and things start to fall apart. Furthermore, just how Facebook has chosen to evolve its platform should give innocent developers pause. As Michael remarked in August, Facebook tends to avoid punishing mischievous developers in any meaningful way. This policy leads to further bad behavior since developers know they won’t be held individually accountable; Facebook will just change the entire platform on them.
And these pending changes only serve to continue that tradition. When installation screens go away mid-July, existing applications will see their access to users grandfathered in. Their profile boxes will be moved over to the new tab, their email lists will retain members, and they will still be able to generate news feed items just as before. Thus, the popular apps that achieved success through spammy means won’t suffer nearly as much as nascent apps that have yet to gain a foothold.
The question going forward, therefore, is this: will Facebook continue perfecting the platform with the goal of preventing all bad behavior with technological measures but no meaningful deterrents? Or will it concede that overly selfish behavior on the part of developers is unstoppable to some extent, and that it’s important to implement a reliable and effective system of punishment?
Crunch Network: CrunchGear drool over the sexiest new gadgets and hardware.


