Monday, March 31, 2008
Behavioral Classification on the Click Graph
Thursday, March 27, 2008

![]()
“Machine Listening” is the idea that computers can be programmed to interpret audio signals the same way humans do. This means that they can tell when a song belongs to the blues genre rather than techno. And they can detect musical characteristics like tempos, transition types, and harmonies.
The technology has some obvious practical uses. It could be used to compile collections of music with the same sound or with similarities to the music someone already knows they like. Applications could also be designed to create the perfect mixtapes, with songs picked and ordered in just the right ways.
The Echo Nest is a company that’s bringing machine listening to Web 2.0. It was founded by two MIT PhD students and is supported by a government grant. Today, the company releases the first of several “Musical Brain” APIs intended to improve three main aspects of music-related web services: search, recommendations, and interactivity.
The first API, which focuses on signature analysis and is being released through Mashery, can be used to retrieve an XML file with information about a particular song. A proof of concept website called This is my jam has been set up to demonstrate its capabilities. Load up a few of your favorite artists and it will automatically arrange songs from them in an order deemed most suitable given their audio characteristics.
The Echo Nest will lend all of its APIs to non-commercial projects for free, but it will charge commercial sites with a usage fee. The company plans on showcasing a website for each of its APIs, but it doesn’t currently have any plans to create a consumer destination of its own with the tech.
Crunch Network: MobileCrunch Mobile Gadgets and Applications, Delivered Daily.
Tuesday, March 25, 2008
Paper: On Designing and Deploying Internet-Scale Services
Greg Linden links to a heavily lesson ladened LISA 2007 paper titled On Designing and Deploying Internet-Scale Services by James Hamilton of the Windows Live Services Platform group. I know people crave nitty-gritty details, but this isn't a how to configure a web server article. It hitches you to a rocket and zooms you up to 50,000 feet so you can take a look at best web operations practices from a broad, yet practical perspective. The author and his team of contributors obviously have a lot of in the trenches experience. Many non-obvious topics are covered. And there's a lot to learn from.
The paper has too many details to cover here, but the big sections are:
In the recommendations we see some of our old favorites:
Friday, March 21, 2008
03/21/08 PHD comic: 'Ph.D. Training'
| Piled Higher & Deeper by Jorge Cham | www.phdcomics.com | |
 | ||
title: "Ph.D. Training" - originally published 3/21/2008 For the latest news in PHD Comics, CLICK HERE! | ||
Wednesday, March 19, 2008
![]() Semantic startups and projects are hot right now. (See Radar Networks, Freebase, Blue Organizer, Hakia, even Yahoo). But what do you do if you are a little-known technology company in Rochester, New York with a powerful semantic-analysis engine on your hands that you want to turn into new businesses?
Semantic startups and projects are hot right now. (See Radar Networks, Freebase, Blue Organizer, Hakia, even Yahoo). But what do you do if you are a little-known technology company in Rochester, New York with a powerful semantic-analysis engine on your hands that you want to turn into new businesses?
You offer a $1 million prize to anyone who can come up with the most profitable application for your technology and call it the Semantic Hacker challenge. The challenge starts today, and is being sponsored by TextWise, a private company backed by pension-fund adviser Bill Manning that has been around since 1994. TextWise uses natural-language processing and semantic analysis to automatically categorize Web pages and create contextual ads for them. But it wants to see what the crowd can do with its technology. It is opening up its APIs, much like semantic search engine Hakia did yesterday. But instead of merely licensing the technology, which it is willing to do, it hopes to generate actual business ideas that it can run with. CEO Connie Kenneally explains how the challenge will work:
The winners of the challenges would turn over rights to their idea. We would award them $100,000 immediately, we would likely make them or their team job offers, and we would build out whatever is required. Then they would receive 50% of the first year’s revenues, up to $1 million.
Not a bad deal for simply coming up with a killer semantic application. Before somebody else takes it, my idea is a semantic search engine that actually works at Web scale (please send the check to my home address). Don’t worry. There can be more than one winner.
 Kenneally is hoping for specific suggestions to apply semantic analysis to different industries. Any idea is fair game, except for four works-in-progress TextWise is already developing: a browser plug-in that replaces ads with content related to the page you are on (foof), semantic bookmarks that bring up related content from the top 6,000 blogs on Technorati (Gyzork), a shopping discovery tool, and a Facebook app that automatically provides shareable links relevant to a given conversation (Festoon). That Gyzork idea is my favorite. Instead of saving bookmarks, you save concepts and the relevant links are added to the bookmark over time.
Kenneally is hoping for specific suggestions to apply semantic analysis to different industries. Any idea is fair game, except for four works-in-progress TextWise is already developing: a browser plug-in that replaces ads with content related to the page you are on (foof), semantic bookmarks that bring up related content from the top 6,000 blogs on Technorati (Gyzork), a shopping discovery tool, and a Facebook app that automatically provides shareable links relevant to a given conversation (Festoon). That Gyzork idea is my favorite. Instead of saving bookmarks, you save concepts and the relevant links are added to the bookmark over time.
The way the technology works is that it creates “Semantic Signatures” from any text that is fed into the system. You put text in and it spits out categories it thinks the text fits under, as well as related Wikipedia articles. On the Semantic Hacker site you can try it out by cutting and pasting some text and seeing what it comes up with. For instance, I put in the text from a post I wrote about China blocking YouTube, and it generated a Semantic Signature with these categories:
Society/Issues/Territorial_Disputes/Tibet 68…/Religion_and_Spirituality/Buddhism/Lineages/Tibetan/Dalai_Lama 48
Society/Religion_and_Spirituality/Falun_Dafa 22
Computers/Internet/Searching/Search_Engines/Google 17
Computers/Internet/Searching/Directories/Volunteer-Edited 17
That is pretty accurate. (The numbers weight the relevance of each category on a scale of 1 to 100). And it produced ten related Wikipedia articles about Tibet as well. “It is like decoding the DNA of the text—creating a semantic map of the text,” explains Kenneally. She says it can scale to hundreds of millions of Web pages, but for the challenge she is limiting applicants to 20,000 separate requests a day, and up to 100,000 characters per request. Unlike, say, the Netflix challenge to come up with a better recommendation engine, TextWise isn’t looking for someone to improve its algorithm, which it is keeping secret. It just wants to know what applications and markets to go after.
If you were going to build a semantic startup, what would it be?
Crunch Network: MobileCrunch Mobile Gadgets and Applications, Delivered Daily.
Tuesday, March 18, 2008
Yahoo Mail Gives Users Trojan Horses
I got this picture from a reader of the site. Apparently the reader was simply viewing Yahoo mail and poof, RogueIframe trojan. We are starting to see a lot more of this kind of stuff, but it’s really disappointing that third party ads are being displayed on otherwise sensitive apps (or at least I think most people feel they are sensitive). Here’s the picture:

Click to enlarge
We’ve seen this exact hack hit before, against Facebook. But I think this kind of thing may be the beginning of a epidemic. As long as you can end up with your advertisements on any site that is even vaguely sensitive, you can start either taking over the site, or delivering malware. Whatever best suits the attacker’s needs. I think this all goes back Tom Stripling’s speech at OWASP where he in painstaking detail explained why you cannot trust third party JavaScript on your site, and yes, that definitely includes advertisements. Anyway, I hope this gets cleaned up quickly.
Monday, March 17, 2008
Paper: Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web
Consistent hashing is one of those ideas that really puts the science in computer science and reminds us why all those really smart people spend years slaving over algorithms. Consistent hashing is "a scheme that provides hash table functionality in a way that the addition or removal of one slot does not significantly change the mapping of keys to slots" and was originally a way of distributing requests among a changing population of web servers. My first reaction to the idea was "wow, that's really smart" and I sadly realized I would never come up with something so elegant. I then immediately saw applications for it everywhere. And consistent hashing is used everywhere: distributed hash tables, overlay networks, P2P, IM, caching, and CDNs. Here's the abstract from the original paper and after the abstract are some links to a few very good articles with accessible explanations of consistent hashing and its applications in the real world.
Closures: Control Abstraction, Method References, Puzzler Solution
Closures: Control Abstraction, Method References, Puzzler Solution
The Java Closures prototype now supports control abstraction and
implements restricted closures and function types. The syntax has
changed slightly. Also, as hinted in the
draft JSR
proposal, there is now support for eta abstraction, which
is called method reference in
Stephen
Colebourne's FCM proposal. We haven't updated the
specification, so this will serve
as a brief tutorial on the changes until we do. I don't know if this
will be the syntax we will end up with, but it will do for now. Finally,
we look at solutions to the closure puzzler in my previous post.
Control Abstraction
The first thing you'll notice when using the new prototype is that
the compiler gives a warning when a closure uses a local variable from an enclosing scope:
Example.java:4: warning: [shared] captured variable i not annotated @Shared
Runnable r = { => System.out.println(i); };
^
There are a few ways to make this warning go away:
- declare the variable
final; or - annotate the variable
@Shared; or - make sure the variable is not the target of any assignment expression; or
- put
@SuppressWarnings("shared")on an enclosing method or class; or - use an unrestricted closure, by using the
==>token
instead of the=>token (when possible).
The => token builds a restricted closure that
triggers this warning. Restricted closures also do not allow abreak or continue statement to a target outside
the closure, nor a return statement from the enclosing method.
You will rarely want to write an unrestricted closure; many (but not all) of
the things you need to do with an unrestricted closure can be expressed more
clearly with a control invocation statement instead.
You're not allowed to assign an unrestricted closure to a restricted
interface. A number of existing JDK interfaces, such asjava.lang.Runnable, have been modified to be restricted.
Error: cannot assign an unrestricted closure to a restricted interface type
Runnable r = { ==> System.out.println(i); };
^
In the less common case that you're writing a method intended to be used as a control
API, you can write a function type with the (new) ==> token to designate
an unrestricted function (interface) type. Let's do that to write a method,with, that will automatically close a stream for us. The idea is to be able
to replace this code
FileInputStream input = new FileInputStream(fileName);
try {
// use input
} finally {
try {
input.close();
} catch (IOException ex) {
logger.log(Level.SEVERE, ex.getMessage(), ex);
}
}
with this
with (FileInputStream input : new FileInputStream(fileName)) {
// use input
}
which is an invocation of the following method
public static void with(FileInputStream t, {FileInputStream==>void} block) {
try {
block.invoke(t);
} finally {
try {
t.close();
} catch (IOException ex) {
logger.log(Level.SEVERE, ex.getMessage(), ex);
}
}
}
This is among the simplest control APIs, but it has some limitations:
- It works with the type
FileInputStream, but not any otherCloseabletypes - It does not support exception transparency
- It does not support completion transparency
Completing the API by repairing these defects is left as an exercise to the reader.
A solution will be discussed in
my
JavaOne talk Closures Cookbook.
Method References
A natural companion to closures is a way to refer to an existing method instead
of writing a closure that accepts the same arguments and just invokes the method. This is
sometimes known as eta
abstraction or method
references. We expect closures in their final form to include support for this
convenient feature, which is why it is called out in the
draft JSR proposal. The
latest version of the prototype supports this, with a syntax based on javadoc conventions.
Here are a few examples:
{ int => Integer } integerValue = Integer#valueOf(int);
{ Integer => String } integerString = Integer#toString();
{ int, int => int } min = Math#min(int, int);
{ String => void } println = System.out#println(String);
{ => String } three = new Integer(3)#toString();
{ Collection<String> => String } max = Collections#max(Collection<String>);
{ => Collection<String> } makeEmpty = Collections#<String>emptySet();
Runnable printEmptyLine = System.out#println();
Writing code as a method is sometimes more convenient than writing it as a closure:
void doTask() {
// a complex task to be done in the background
}
Executor ex = ...;
ex.execute(this#doTask());
Puzzler Solution
A couple of weeks ago we looked at
a
Java puzzler involving closures, and a number of people discussed the underlying issue. My favorite is David's post "Color-flavor locking breaks chiral symmetry". Lessons include not exposing public fields (accessors are better) and being careful to avoid cyclic initialization dependencies.
The enum language feature provides support for one solution to the puzzle: specialize each instance of the enums.
import java.util.*;
enum Color {
BROWN {
public Flavor flavor() {
return Flavor.CHOCOLATE;
}
},
RED {
public Flavor flavor() {
return Flavor.STRAWBERRY;
}
},
WHITE {
public Flavor flavor() {
return Flavor.VANILLA;
}
};
abstract Flavor flavor();
}
enum Flavor {
CHOCOLATE {
public Color color() {
return Color.BROWN;
}
},
STRAWBERRY {
public Color color() {
return Color.RED;
}
},
VANILLA {
public Color color() {
return Color.WHITE;
}
};
abstract Color color();
}
class Neapolitan {
static <T,U> List<U> map(List<T> list, {T=>U} transform) {
List<U> result = new ArrayList<U>(list.size());
for (T t : list) {
result.add(transform.invoke(t));
}
return result;
}
public static void main(String[] args) {
List<Color> colors = map(Arrays.asList(Flavor.values()), { Flavor f => f.color() });
System.out.println(colors.equals(Arrays.asList(Color.values())));
List<Flavor> flavors = map(Arrays.asList(Color.values()), { Color c => c.flavor() });
System.out.println(flavors.equals(Arrays.asList(Flavor.values())));
}
}
Another elegant solution, due to 5er_levart, uses closures:
enum Color {
BROWN({=>Flavor.CHOCOLATE}),
RED({=>Flavor.STRAWBERRY}),
WHITE({=>Flavor.VANILLA});
private final {=>Flavor} flavor;
public Flavor flavor() { return flavor.invoke(); }
Color({=>Flavor} flavor) {
this.flavor = flavor;
}
}
enum Flavor {
CHOCOLATE({=>Color.BROWN}),
STRAWBERRY({=>Color.RED}),
VANILLA({=>Color.WHITE});
private final {=>Color} color;
public Color color() { return color.invoke(); }
Flavor({=>Color} color) {
this.color = color;
}
}
In both solutions the idea is to compute the value lazily, a key technique to break dependency cycles.
Saturday, March 15, 2008
Security In IE7 & IE8.
The XDR object.
xdr = new XDomainRequest();
xdr.open('POST', 'http://www.mr.bigglesworth.com');
xdr.send(data);
Now, Mr.Bigglesworth needs to approve the send XDomainRequest header, but we can approve the call by returning this header to the server that requested legitimacy:
Response.AppendHeader("XDomainRequestAllowed","1");
Great, XSS made easy. No need for hijacked iframes, css or images. Nope pure Javascript does the trick for us. This obviously can bypass many XSS filters in use today, so if you run one be sure to check this beast out. In my opinion this will broaden the attack landscape since there are more ways of launching XSS or spreading worms. The XDR object also returns the responseText that gives access to:
xdr.onerror
xdr.ontimeout
xdr.onprogress
xdr.onload
xdr.timeout
Useful, if you're into worms and all.
next, I saw that they implemented cross-document messaging in the form of the object postMessage. Opera already has it, and from a security standpoint I don't trust it. It basically means that a webpage can write into another page that is running in the same session and on the same host by attaching an event listener. Spoofing comes to mind, and maybe other attacks as well. The real question is of course: what is it for? I don't know.
Implementing it is a breeze:
page 1:
var doc = document.getElementsByTagName('iframe')[0];
doc.contentWindow.postMessage('Hello Mr. Bigglesworth!');page 2:
document.attachEvent('onmessage',function(e) {
if (e.domain == 'example.com') {
if (e.data == 'Hello Mr. Bigglesworth!') {
e.source.postMessage('Meow! Meow! Dr. Evil!');
} else {
alert(e.data);
}
}
});Hash write access.
Another thing that caught my eye was write access to the hash of an url. Doesn't sound smart because I don't want Javascript to manipulate the hash. Not only can it be annoying, it can lead to security issues depending on the setting of your website.
Webslices.
If I understand it correctly this feature allows users to favorite the slice or put it in their feed reader. Better expect some buffer overflows here since IE8 now listens for a tag called 'hslice' on any page it opens, would be nice to fuzz this feature.
<div class="hslice" id="main">
<h2 class="entry-title">All I want are friggin' sharks with friggin' lazer beams attached to their heads! </h2>
</div>
GlobalStorage & SessionStorage.
IE8 jumped on the Mozilla bandwagon and implemented the Session object. I can't say I'm that impressed because I as I said before; allowing 10MB of data to be stored in such object (XML file in IE8) isn't smart. Let alone the permanent storage of user tracking details, XSS worms and other spy-ware.
IE8 GlobalStorage
<script>
var storage = globalStorage[location.hostname];
storage.some_string = '
Ladies and Gentlemen welcome to my underground lair.
I have gathered here before me the worlds deadliest assassins.
And yet each of you has failed to kill Austin powers.
That makes me angry. And when Dr. Evil get angry, Mr. Bigglesworth gets upset.
And when Mr. Bigglesworth gets upset...people DIE!!!
Why must I be surrounded by freakin idiots. Mustafa, Frau Farbissina...
';
</script>
Reverse Engineering IE7 & IE8.
Okay, this is fun. I'm going to show you a couple things I found out about Internet Explorer. First off IE8 prevents header forwards on files, pity this was pretty 'evil' in MSIE 7 where it is still possible to change the location of a file to a local file stored on your computer. It's very simple:
<?
header("location: localfile ");
?>
And IE7 follows it, whereas IE8 refuses to follow.
The reason why this is dangerous is because of this XML file that contains system information which we could parse. Useful for reconnaissance and possibly other attack schemes.
<?
header("location: res://ieframe.dll/24/123");
?>
Results in IE7:
<?xml version="1.0" encoding="UTF-8" standalone="yes" ?>
- <!-- Copyright (c) Microsoft Corporation
-->
- <assembly xmlns="urn:schemas-microsoft-com:asm.v1" xmlns:asmv3="urn:schemas-microsoft-com:asm.v3" manifestVersion="1.0">
<assemblyIdentity name="Microsoft.Windows.InetCore.ieframe"processorArchitecture="x86" version="5.1.0.0"
type="win32" />
<description>Windows IE</description>
- <dependency>
- <dependentAssembly>
<assemblyIdentity type="win32"name="Microsoft.Windows.Common-Controls"version="6.0.0.0" processorArchitecture="*"
publicKeyToken="6595b64144ccf1df" language="*"
/>
</dependentAssembly>
</dependency>
- <trustInfo xmlns="urn:schemas-microsoft-com:asm.v3">
- <security>
- <requestedPrivileges>
<requestedExecutionLevel level="asInvoker" uiAccess="false" />
</requestedPrivileges>
</security>
</trustInfo>
- <asmv3:application>
- <asmv3:windowsSettings xmlns="http://schemas.microsoft.com/SMI/2005/WindowsSettings">
<dpiAware>true</dpiAware>
</asmv3:windowsSettings>
</asmv3:application>
</assembly>
If you notice correctly I read res://ieframe.dll/24/123 located on ieframe.dll which is the IEDataObjectWrapper (InProcServer32) I don't know why they still allow this to be browsable, because you can resource it on iframes, XML and as a Javascript source. So I went further to find all data object in IE8 and a few in IE7.
IE7/8 data sources are:
res://ieframe.dll/MUI/1
res://ieframe.dll/TYPELIB/1
res://ieframe.dll/UIFILE/{20481,20482,20483,20484,20484,20485,20486,20487,39216,41555}
res://ieframe.dll/WEVT_TEMPLATE/1
res://ieframe.dll/Version Info/1
res://ieframe.dll/23/ABOUT.js
res://ieframe.dll/23/ANALYZE.js
res://ieframe.dll/23/ANCHBRWS.js
res://ieframe.dll/23/DOCBROWS.js
res://ieframe.dll/23/ERROR.js
res://ieframe.dll/23/HTTPERRORPAGESSCRIPTS.js
res://ieframe.dll/23/IEERROR.js
res://ieframe.dll/23/IMGBROWS.js
res://ieframe.dll/23/INVALIDCERT.js
res://ieframe.dll/23/ORGFAV.js
res://ieframe.dll/23/PHISHSITE.js
res://ieframe.dll/23/POLICY.js
res://ieframe.dll/23/PREVIEW.js
res://ieframe.dll/preview.dlg (dialog)
res://ieframe.dll/23/PSTEMPLATES.js
res://ieframe.dll/24/123 (XML file)
IE6 has a few too:
res://mshtml.dll/REGINST/REGINST
res://mshtml.dll/23/ABOUT.MOZ
res://mshtml.dll/23/BLANK.HTM
res://mshtml.dll/23/REPOST.HTM
As well as others.
These are nice to play with some more, I haven't digged any deeper yet but this is quite nice to have a look at. So, enough building blocks to pentest IE a little further. If you find anything notable, do let me know.
Have fun.
Wednesday, March 12, 2008

Get that job at Google
Video captioning made easy with the YouTube JavaScript API
One thing that has been annoying me for ages is that no video player on the web allows you to write comments for a specific time in the video that get displayed as plain text. Viddler allows you to comment at a certain time and it appears in the video, but the benefits of time based captioning both in terms of accessibility and SEO didn’t quite transpire to any video site maintainers yet. Edit: Darn, I hadn’t looked at Viddler for a long time, it actually does this now, well done!
Google just released a JavaScript API for YouTube which makes it dead easy to control a video with JavaScript. You can start, stop and jump to a certain time of the video but more importantly – you have events firing when something happens to the player. This made it easy for me to whip up a proof of concept how time-based captioning might work as an interface. Click the screenshot to see it in action.

Start the video and hit the pause button to add a new caption. You can delete captions by hitting the x links and you can jump back to the section of the video by clicking the time stamp.
Check the source for how it is done. In order to make this a service, all you need to do is have a backend script that gets all the form fields and store it in a DB.
Technorati Tags: accessibility, captioning, video, youtube, api, javascript
Half-Assed Startup: How do I start my company and keep my day job?
[Ed: I enjoyed Tony Wright’s contrarian article, Half-Assed Startup, when I first read it on his excellent blog. Tony, a founder of RescueTime (Y Combinator), argues that you can start a company while you’re otherwise employed. And he explains how to do it. Tony kindly agreed to re-publish his article on Venture Hacks. Take it away Tony.]
 I’ve done two part-time-to-full-time startups. One was acquired by Jobster. The second startup is RescueTime—currently a Y Combinator funded company—cross your fingers.
I’ve done two part-time-to-full-time startups. One was acquired by Jobster. The second startup is RescueTime—currently a Y Combinator funded company—cross your fingers.
At the end of the day, I think Paul Graham has it right in How Not to Die:
“The number one thing not to do is other things. If you find yourself saying a sentence that ends with “but we’re going to keep working on the startup,” you are in big trouble. Bob’s going to grad school, but we’re going to keep working on the startup. We’re moving back to Minnesota, but we’re going to keep working on the startup. We’re taking on some consulting projects, but we’re going to keep working on the startup. You may as well just translate these to “we’re giving up on the startup, but we’re not willing to admit that to ourselves,” because that’s what it means most of the time. A startup is so hard that working on it can’t be preceded by “but.”"
In the beginning, however, it’s not always practical to dive in full-time. And when your idea is off-the-wall and easy to prototype, it’s smart to whip something out just to see if it’s as cool as you think it might be—before you take the full-time plunge.
So if you’re too poor or too unsure to do the right thing for your business and dive in full-time, here are a few things that seemed to work for us when we did it part-time:
- You need a co-founder and some cheerleaders. If you can’t find two or three friends who are really excited to be beta testers for your product, ponder changing your direction. In a part-time effort, a co-founder is essential to keeping you on-track and working. At some point, you’ll hit a motivation wall… but if you have a partner who is depending on you, you will find a way past that. If you don’t have a partner, you’ll often lose interest and find something else to entertain you.
- Pick a day or two per week where you always work, ideally in the same room as your co-founders. Always, no exceptions. We worked one weekday evening and one weekend day. That doesn’t mean we weren’t working other days, but keeping a fixed schedule helps you through the phases of the project that might not be so fun.
- Have a boat-burning target. What will it take for everyone to dive in full-time? 5,000 active users? 10,000 uniques a week? Funding? The target should be a shared understanding. You don’t want one founder who is ready to go full-time while the other has reservations. This is easy to gloss over, but you should really nail it down. I’ve lost two co-founders who weren’t ready to dive in full time when I was. It wasn’t fair to them and it wasn’t fair to me.
- Pick an idea that is tractable. Every startup is a hypothesis. If your hypothesis is, “we can build a better web-based chat client”, that’s something you could test quickly. If your hypothesis is “we can build a car that runs on lemonade”, that’s just not going to work as a part-time effort. The scarcity of available time should force you to distill the idea to the absolute minimum that is necessary to test the hypothesis. No extraneous features!
- Understand that your first version is probably going to suck. Read David Rusenko’s article, The importance of launching early and staying alive. David is a founder of Weebly (Y Combinator). It’s a long road. My second startup was a ridiculous fluke—it was acquired after 2 months. 99% of overnight successes were slogging in the muck for 5 years before the night in question. Be prepared for a long journey and be surprised if your startup is an immediate hit. So with your first version, look for the tiny little flicker than you might be onto something. And use it to motivate you to make it better. Every week, make it better than last week and see if that flicker of light can be fanned into a tiny flame.
- If you’re going to screw off at work (everyone does), spend it getting smarter about the stuff you don’t know. If you’re a coder, read a few design or usability blogs. Read up on what motivates angel investors. Research competitors and write down what they do well. Get brilliant at SEO (it’s not hard). Write a lot more (blogging helps). Think about virality and research the heck out of it. That said, be aware of the fuzzy line between using your cool-down time at work for your startup and stealing time or resources from your employer. If you’re paid to do a job, you need to do it.
- Be sure you own your startup. I’ve had the fortune of working in companies where there was very clear ownership of “after hours” work. If ownership of your personal intellectual property is not clear, do not rely on the good will of your employer. Greed can do funny things to people, even if they were initially big supporters of your startup. (Thanks to Ivan from TipJoy for this final suggestion.)
In short, you want to prove whatever you need to prove as quickly as possible, so you can dive in full-time. Near as I can tell, there are plenty of startups that have started as “hobbies”, but you need to take it out of that phase as soon as you can. There is nothing that drives a team forward like the fear of public failure, debt, and starvation. Leap off the cliff and start building the airplane on the way down—you might be surprised with what you can pull off.
Tuesday, March 11, 2008
Team Whiteboarding with Twiddla
![]() If your team is spread out over a wide geographic region, online collaboration tools are key to getting everyone on the same page. Something that dispersed teams haven't had much opportunity to use use are whiteboards, which can be really useful in brainstorming sessions. But now, with Twiddla, this year's winner of the Technical Achievement award at SXSW, comes a team whiteboarding service that offers a no-setup, online meeting web site for team collaboration.
If your team is spread out over a wide geographic region, online collaboration tools are key to getting everyone on the same page. Something that dispersed teams haven't had much opportunity to use use are whiteboards, which can be really useful in brainstorming sessions. But now, with Twiddla, this year's winner of the Technical Achievement award at SXSW, comes a team whiteboarding service that offers a no-setup, online meeting web site for team collaboration.
Twiddla can be used to mark up web sites, graphics, photos, or even start brainstorming on a blank canvas. Users can either sign up for the service by creating an account, or can just start using it in "guest mode." A public sandbox is also available if you just want to check it out to see if it would work for you.
If you do decide to use it to set up your own meetings, you can set them as either "public" or "private" and email invitations to your intended participants. Meeting participants are displayed in Twiddla's sidebar and with just a click, you can start chatting with them using an audio chat feature that utilizes your computer's microphone and speakers to take the brainstorming session from a chat session to a live conference call.
 Image from the Twiddla blog
Image from the Twiddla blog
The whiteboard tool in Twiddla lets you draw freehand, insert shapes, insert text, and insert media. You can use Twiddla's built-in shapes or upload files from your own computer. Text can be entered in directly or can be placed in a text bubble or on a post-it note. A box at the top of the screen lets you enter in a URL of your choosing to pull up any web site on the internet. You can then overlay your drawings on top of the web site that is displayed.
But I think the Twiddla team sums it up the best. When I clicked over to their "features" page, only two items were mentioned: "Kicks A**, Doesn't Cost Anything."
I'd like to add to that list: Works.
Twiddla is now in public beta.
Monday, March 10, 2008
Buggiest Browser.
I should really invoice Microsoft for those spent years of browser agony! here is some, a good example on how to crash MSIE. I forgot to mention that it needs a strict doctype to crash properly, ah well.
http://www.gtalbot.org/BrowserBugsSection/MSIE7Bugs/
Sunday, March 9, 2008

Saturday, March 8, 2008

Audiogalaxy.com Architecture
Update 3: Always Refer to Your V1 As a Prototype. You really do have to plan to throw one away.
Update 2: Lessons Learned Scaling the Audiogalaxy Search Engine. Things he should have done and fun things he couldn’t justify doing.
Update: Design details of Audiogalaxy.com’s high performance MySQL search engine. At peak times, the search engine needed to handle 1500-2000 searches every second against a MySQL database with about 200 million rows.
Search was one of most interesting problems at Audiogalaxy. It was one of the core functions of the site, and somewhere between 50 to 70 million searches were performed every day. At peak times, the search engine needed to handle 1500-2000 searches every second against a MySQL database with about 200 million rows.
Thursday, March 6, 2008
Firecookie: Put you hand in the cookie jar with Firebug
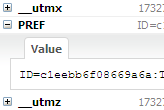
Jan Odvárko "missed two movie nights" to create cookie support in Firebug. His Firebug plugin, Firecookie, gives you access to view, search, create, remove, and manage the permissions of a cookie, all from within a Firebug tab.
Firecookie creates a log entry every time when a cookie is created, changed, deleted or rejected (an option you can change).
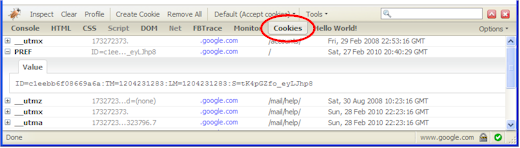
Jan is looking for comments.
He has also written a nice tutorial on extending Firebug. It is great to see sub-plugins for Firebug such as YSlow, Firecookie, etc. Do you know of any other good ones?
NOTE: There are, of course, separate Firefox plugins for cookie management.
Wednesday, March 5, 2008
Yahoo! FireEagle: Personal Location Service Platform for Developers
Today FireEagle launched as an invitation-only beta for developers to start testing. I think of it as a personal location service platform, but the more formal description comes from the announcement on the YDN blog:
Fire Eagle is an open location services platform offering web, mobile, and desktop developers a simple way to build new location-based applications while also ensuring that consumers have complete control over their data, including how, when and where their location is made available. Want to easily make your site responsive to a user's location? Or, maybe you've found a way to capture someone's location and you want to find cool apps to plug it into? By doing the heavy lifting and connecting you to a community of geo-developers, Fire Eagle makes it easier to build location-aware services.
Tom Coates was the ring leader for FireEagle and talks about it in this video shot earlier today at ETech 2008.
Don't be put off by the downer of a headline that TechCruch used ("Yahoo’s “Twitter For Location” Goes Into Private Beta With Near Zero Functionality"). I think that Mike Arrington either got the wrong message from someone or misunderstood what FireEagle really is today.
It's a location platform for developers to build on. It has an API that, among other things, lets you worry less about handling geo data and easily build in support for your web, desktop, or mobile application.
It's currently not aimed at end users or "consumers" (oh, how I hate that term). I'm sure the analogy to Twitter was intended to be a loose one.
Congrats to Tom and team for getting FireEagle out the door. :-)
VentureBeat has good coverage here: Yahoo’s FireEagle location service to launch publicly today
Oh, BTW... FireEagle uses OAuth for authentication!
(comments)
$2.50 placebo gives more relief than a 10 cent one [NYT]
Dina Kaplan sent me this article about human nature and how we tend to value higher priced items just because they are higher priced:
More Expensive Placebos Bring More Relief
Monday, March 3, 2008

Track Clicks in Emails and Web Pages Using Google Analytics
 Most use Google Analytics to track simple metrics like page views, what keywords do people type in search engines before they land on our website, where the visitors are coming from, what pages are most popular and so on.
Most use Google Analytics to track simple metrics like page views, what keywords do people type in search engines before they land on our website, where the visitors are coming from, what pages are most popular and so on.
Now this kind of data can be collected using any other web stats program so here we explore some more powerful “click tracking” features of Google Analytics.
Track Clicks in Email Messages and RSS Feeds
Say you have written a wonderful article that fellow bloggers may like to blog about. You are likely to send them an email with a link to the story but how do you track if people actually clicked on that email link ?
Enter URL Builder - a free tool from Google Analytics. Just type the URL of your blog article and put the following values (Campaign Source=<Your Website Name>, Campaign Medium=”email”, Campaign Name=<Title of your Blog Post>)
Press the Generate URL button and send that new tagged link in your email message. Here’s a sample URL after tagging:
http://www.labnol.org/?utm_source=Digital-Inspiration&utm_medium=email&utm_campaign=My-Great-Article
 To see how well your email performed, go to Traffic Sources -> Campaign and select the campaign name (which in this case is “My Great Article”).
To see how well your email performed, go to Traffic Sources -> Campaign and select the campaign name (which in this case is “My Great Article”).
You can extend this idea for tracking clicks to your site that may have originated from RSS newsreaders or even blog newsletters that are sent via FeedBlitz or FeedBurner.
Track Clicks on Links That Point to External Websites
Say one of your articles links to a story on CNN website or contains an affiliate link that points to some product on Amazon.com. How do you track which external links are popular with your site visitors ?
Fortunately Google Analytics offers a very easy way for tracking outbound clicks or links to pages that are on external websites (e.g. CNN.com). Just append the onClick attribute to your <a> tag as shown here:
<a href=”http://www.cnn.com” onClick=”javascript:urchinTracker(’/external/cnn.com’);>CNN</a>
You can then see the number of clicks to CNN.com from your own website by opening the Content -> Top Content report of Google Analytics.

If you have a large website, adding this urchinTracker function to every external link manually may be very tedious so here’s an alternative - add this small javascript from iqBlog to your website and all your outbound clicks with be tracked automatically.
Track Document Downloads (like Word Docs, PDF, MP3, etc)
If you link to files like PDFs, Word Documents, MP3 songs, Video Podcasts, etc that visitors can download from your website, consider using Google Analytics to track downloads so you have a good understanding of non-HTML content that is popular on your site.
Tracking file downloads with Google Analytics is easy - just add the following onlick function to your <a> tag.
<a href=”http://www.labnol.org/assets/downloads/pdf/How-To-Use-Google-Alerts.pdf” onClick=”javascript: pageTracker._trackPageview(’/downloads/GoogleAlerts’); “>
If the manual approach of tagging every link sounds impractical, get this javascript file from GoodWebPractices.com and put it anywhere before the Urchin code in your blog template. It will track all file downloads from your site automatically without you have to tag any link.
To see the statistics for file downloads and, navigate to the “Content” section then select “Top content”.
Google Analytics - More Advanced Techniques
Want more ? Watch these video presentations by Analytics gurus Alex Ortiz and Avinash Kaushik - they definitely know Analytics better than anyone else.
Track Clicks in Emails and Web Pages Using Google Analytics - Digital Inspiration


